
조앤의 기술블로그
[대학원] 면접준비 - 자료구조 (+ 알고리즘) 본문
Q) Sorting Algorithm 에는 어떤 것들이 있는가?
Q) Insertion sort, heap sort, selection sort, quick sort 중 optimal 한 것과 optimal 하지 않은 알고리즘은 ? 그 이유는?
Q) In-place, Stable
Q) quick sort의 worst case는 언제 발생하며 그때의 시간복잡도는?
[Quick Sort]
* Charles Antony Richard Hoare가 개발한 정렬 알고리즘
* stable하지 않음. 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속한다.(?)
* 분할정복 알고리즘의 하나로, 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법
- merge sort와 달리 퀵 정렬은 리스트를 비균등하게 분할한다.(?)
* 분할 정복(divide and conquer) 방법
- 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략.
- 분할 정복 방법은 대개 순환 호출을 이용하여 구현함.
* 과정 설명
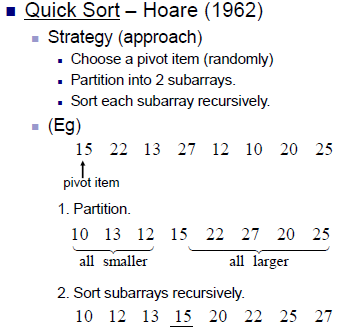
1) 리스트 안에 있는 한 요소를 선택한다. 이렇게 고른 원소를 pivot이라고 한다.
2) pivot을 기준으로 pivot보다 작은 요소들은 모두 pivot의 왼쪽으로 옮겨지고, pivot보다 큰 요소들은 모두 오른쪽으로 옮겨진다. (피봇을 중심으로 왼쪽 - 피봇보다 작은 요소들, 오른쪽 - 피봇보다 큰 요소들)
3) 피봇을 제외한 왼쪽 리스트와 오른쪽 리스트를 다시 정렬한다.
- 분할된 부분 리스트에 대하여 순환 호출을 이용하여 정렬을 반복한다.(?)
- 부분 리스트에서도 다시 피봇을 정하고 피봇을 기준으로 2개의 부분 리스트로 나누는 과정을 반복한다.
4) 부분 리스트들이 더이상 분할이 불가능할 때까지 반복한다.
- 리스트의 크기가 0이나 1이 될 때까지 반복한다.
<퀵정렬 알고리즘의 구체적인 개념>
* 하나의 리스트를 pivot을 기준으로 두 개의 비균등한 크기고 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법
* 단계
- 분할(divide) : 입력 배열을 피봇을 기준으로 비균등하게 2개의 부분 배열로 분할한다. (왼쪽 - 작은, 오른쪽 - 큰)
- 정복(conquer) : 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 방법을 적용한다.
- 결합(combine) : 정렬된 부분 배열들을 하나의 배열에 합병한다.
- 순환 호출이 한 번 진행될 때마다 최소한 하나의 원소(pivot)는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
<퀵정렬 알고리즘의 특징>
* 장점
1) 속도가 빠르다.
- 시간복잡도가 O(nlogn)을 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
2) 추가 메모리 공간을 필요로 하지 않는다. (in-place)
- 퀵 정렬은 O(logn)만큼의 메모리를 필요로 한다.
* 단점
1) 정렬된 리스트에 대해서는 퀵정렬의 불균형 분할에 의해 오히려 수행시간이 더 많이 걸린다.
* 퀵정렬의 불균형 분할을 방지하기 위하여 피벗을 선택할 때 더욱 리스트를 균등하게 분할할 수 있는 데이터를 선택한다.
(리스트 내의 몇 개의 데이터 중에서 크기 순으로 중간값(medium)을 피벗으로 선택한다...?)
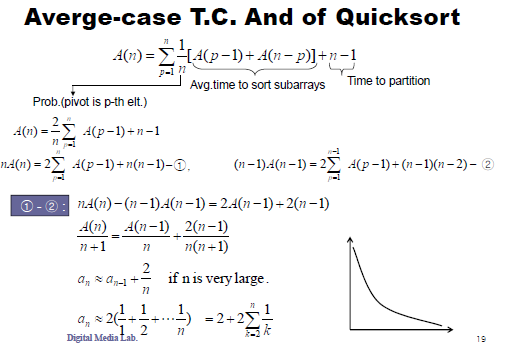
<퀵정렬의 시간복잡도>
* best case : O(nlogn)
* worst case : O(n^2)
- 리스트가 계속 불균형하게 나누어지는 경우, 특히 이미 정렬된 리스트에 대하여 퀵정렬을 실행하는 경우)
* average case : O(nlogn)





[Merge Sort]
* Jon von Neumann(존 폰 노이만)이 제안한 방법
* 안정 정렬(stable). 분할 정복 알고리즘의 하나이다.(?)
* 과정 설명
1) 리스트의 길이가 0 또는 1이면 이미 정렬된 것으로 본다. 그렇지 않은 경우에는
2) 정렬되지 않은 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.
3) 각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
4) 두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.
<머지 소트의 구체적인 개념>
* 하나의 리스트를 두 개의 균등한 크기로 분할하고, 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법
* 단계
- 분할(divide) : 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
- 정복(conquer) : 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 방법을 적용한다.
- 결합(combine) : 정렬된 부분 배열들을 하나의 배열에 합병한다.
* 과정
- 추가적인 리스트가 필요하다. (not in-place)
- 각 부분 배열을 정렬할 때도 머지 소트를 순환적으로 호출하여 적용한다.
- 머지소트에서 실제로 정렬이 이루어지는 시점은 2개의 리스트를 merge하는 단계이다.
<머지소트 알고리즘의 특징>
* 단점
- 만약 레코드를 배열로 구성하면, 임시 배열이 필요하다. (not in-place)
- 레코드들의 크기가 큰 경우에는 이동 횟수가 많으므로 매우 큰 시간적 낭비를 초래한다.
* 장점
- 안정적인 정렬방법이다.
—데이터의 분포에 영향을 덜 받는다. 즉, 입력 데이터가 무엇이든 간에 정렬되는 시간은 동일하다. (O(nlogn))
- 만약 레코드를 linked list로 구성하면, 링크 인덱스만 변경되므로 데이터의 이동은 무시할 수 있을 정도로 작아진다.?
— in-place 로 구현할 수 있다...?
- 따라서 크기가 큰 레코드를 정렬할 경우에 연결 리스트를 사용한다면, 머지소트는 퀵정렬을 포함한 다른 어떤 정렬 방법보다 효율적이다.
[Heap Sort]
* 최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법
* 내림차순 정렬을 위해서는 최대 힙 구성. 오름차순 정렬을 위해서는 최소 힙 구성
* 과정
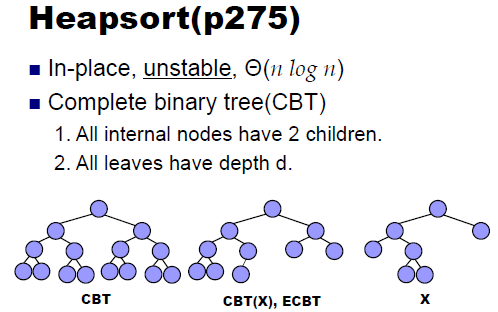
1) 정렬해야 할 n개의 요소들로 최대 힙(완전 이진 트리 complete binary tree)을 만든다. (내림차순 기준)
2) 다음으로 한번에 하나씩 요소를 힙에서 꺼내서 배열의 뒤부터 저장하면 된다.
3) 삭제되는 요소들(최댓값부터 삭제)은 값이 감소되는 순서로 정렬되게 된다.
-힙(heap)은 최댓값 또는 최솟값을 빠르게 찾아낼 수 있는 트리형 자료구조이다. (Max heap, Min heap)
-힙은 완전이진트리(CBT) 형식을 따르며 모든 부모 노드의 값이 자식 노드들의 값과 일정한 대소 관계를 가지게 되는 규칙을 가지고 있다. 또한 자식노드 사이의 상관관계는 없으므로 유의하여야 한다.
-부모 노드의 값이 자식 노드의 값보다 크다면 최대 힙(Max Heap), 부모 노드의 값이 자식 노드의 값보다 작다면 최소 힙(Min Heap)으로 부른다.
-힙의 규칙에 따라 트리의 가장 상단에는 최댓값 또는 최솟값이 있는 것이 자명하기 때문에, O(1)만에 최댓값과 최솟값을찾을 수 있다.



[슈도코드]
parent * 2 == child1, parent * 2 + 1 == child2

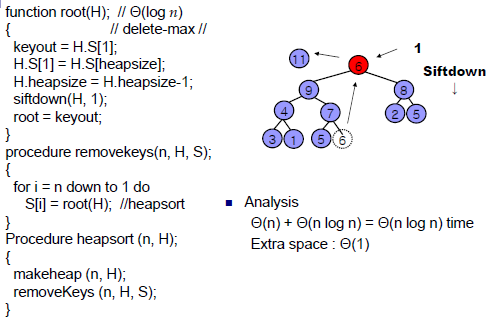
[시간복잡도]




Q) 그래프의 정의는 ? 트리의 정의는 ? 트리와 그래프의 관계는?
Q) tree travesal의 3가지 방식을 설명하시오
[Tree]
그래프의 일종. 여러 노드가 한 노드를 가리킬 수 없는 구조.
회로가 없고, 서로 다른 두 노드를 잇는 길이 하나뿐인 그래프를 트리라고 부른다.
[Tree 순회 방식]
-preorder : root-left subtree-right subtree
-in-order : left - root - right
-post-order : left - right - root
-level-order ?
[Graph]
vertex와 edge로 이루어진 자료구조(vertex : 정점, edge : 간선)
Q) topological sorting을 설명하시오
Topological sort란 Directed Acyclic Graph(방향을 가지면서 사이클이 없는 그래프)를 활용해 노드들 사이에 선후관계를 중심으로 정렬하는 알고리즘. 이때 사용되는 기법이 DFS이다.
그래프를 DFS로 모든 노드를 탐색하고, 노드들에 방문시점 / 방문종료시점을 기록해둔다.
이후 방문종료시점의 내림차순으로 정렬한다.
계산복잡성은 DFS에 비례한다.
따라서 O(|V|+|E|)가 된다.
[DAG 최단거리]
Topological Sort와 edge relaxation 기법을 활용해 Directed Acyclic Graph(DAG)의 최단거리를 구할 수 있다.
* 주어진 DAG에 대해 topological sort을 수행한다.
* 시작노드를 0, 나머지 거리를 무한대로 초기화한다.
* 각 노드별 엣지에 대해 edge relaxation을 수행한다.
위상 정렬, 유향그래프에서 정해진 순서를 위배하지 않도록 나열하는 것.
(전략게임의 빌드 오더 - A를 짓지 않으면 B를 지을 수 없고, B를 짓지 않으면 C를 지을 수 없다. ,선수과목 - 자료구조 과목을 듣지 않으면 알고리즘 과목을 수강할 수 없다.
그래프에서는 A->B라면 A를 방문해야 B를 방문할 수 있다. )
만약에 이런 규칙에 순환이 생긴다면 순환이 생긴 그 무엇도 나열할 수 없기 때문에 DAG(directed acylic graph)에서만 위상 정렬이 가능하다.
내부 간선(Incoming Edge)이 존재한다는 것은 자기 자신을 방문하기 전에 방문해야 할 정점들이 남아있다는 것이고, 현재 수행 불가능하다는 것을 의미한다. (따라서 InDegree가 0인 정점들만 방문이 가능한 정점이고, 나머지들은 자신의 차례가 오기를 기다리는 정점들이다.)
정점을 방문하였을 때 자신과 연결된 간선들을 지워나가는 방식을 사용하면 DAG에서 모든 정점을 방문할 수 있다.
알고리즘 구현방법은 두가지 : Kahn의 알고리즘, DFS를 이용한 방법
1.Kanh의 알고리즘 …
2.DFS이용
: 모든 정점을 반복문을 돌면서 내부 간선이 0인 정점인지 확인하여 DFS를 돌린다. 돌다가 더 이상 이동할 수 있는간선이 없을 경우 해당 정점을 List의 앞에 넣어준다. 이러한 과정을 반복하면 List에 위상정렬의 결과가 들어가게된다.



Q) partially ordered set 이란?
Q) NP Complete의 정의는?
[클래스 P]
어떤 문제에 대해서 Polynomial Time Algorithm이 존재하면 그 '문제'는 클래스 P에 속한다.
(다항시간 알고리즘)
n^k 형태로 Worst time Complesity가 정의되는 알고리즘 (k는 상수)
=> 어떤 문제에 대해 Polynomial Time, 즉 다항시간에 그 문제에 대한 solution을 찾아낼 수 있으면 (=Polynomial Time Algorithm이 있으면) 그 문제는 클래스 P에 속한다.
[클래스 NP]
Non-Deterministic Polynomial Time
그 문제를 해결하는 Non-Deterministic Polynomial Time algorithm이 존재하면, 그 문제는 클래스 NP에 속한다.
비결정적 다항시간.... 같은 인풋이 들어가도 다른 아웃풋을 낼 수 있는 알고리즘. 다항시간에.
하지만 어쩔때는 다항시간에 끝나지 않을 수도 있다.
(비결정적 다항시간 알고리즘이 존재하면-> 클래스 NP에 속한다.)
[NP-hard]
NP클래스 안에 있는 모든 문제가 어떤 문제(Q)로 reducible하면 그 문제 Q는 NP-hard이다.
NP클래스 안에 있는 모든 문제들보다 Q가 어렵거나 같다.
[NP-Complete]
NP-hard이면서 NP클래스 안에 있으면 NP-Complete이다.
NP클래스에 속해있으면서, 어떤 기준에 의해 가장 어려운 문제이면 NP-Complete이다.
Q) Dynamic Programming이란?
[Dynamic Programming]
이상한 나라의 동전.
큰 문제를 작은 문제로 나누어 푸는 알고리즘
입력크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서, 보다 큰 크기의 부분 문제를 해결, 최종적으로 문제를 해결하는 알고리즘.
상향식 접근법으로 가장 최하위 해답을 구한 후, 이를 저장하고 해당 결과값을 이용해서 상위 문제를 풀어가는 방식
Memorization 기법을 사용함 (프로그램 실행 시 이전에 계산한 값을 저장하여, 다시 계산하지 않도록 하여 전체 실행 속도를 빠르게 하는 기술)
문제를 잘게 쪼갤 때 부분 문제는 중복되어 재활용됨
ex) 피보나치 수열
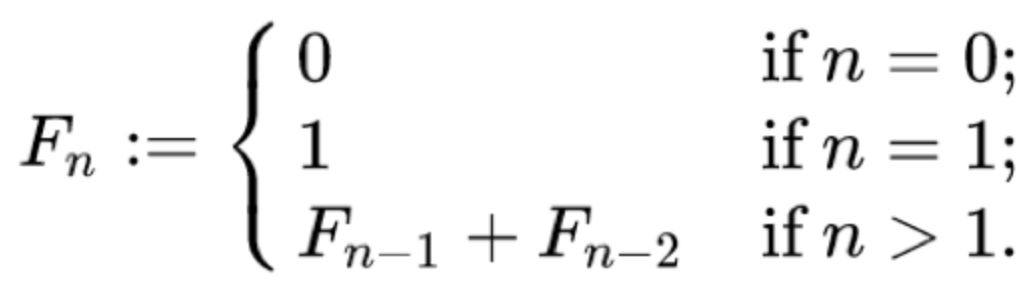
[분할 정복]
문제를 나눌 수 없을 때까지 나누어서 각각을 풀면서 다시 합병하여 문제의 답을 얻는 알고리즘.
하향식 접근법으로 상위의 해답을 구하기 위해 아래로 내려가면서 하위의 해답을 구하는 방식(일반적으로 재귀함수로 구현)
문제를 잘게 쪼갤 때, 부분 문제는 서로 중복되지 않는다.
*공통점
문제를 잘게 쪼개서 가장 작은 단위로 분할
*차이점
- DP : 부분 문제는 중복되어 상위 문제 해결시 재활용됨. Memorization 기법 활용
- Divide and Conquer : 부분 문제는 서로 중복되지 않음. Memorization 기법 사용 안함
Q) priority queue란? heap 이란?
[priority queue]
* 우선순위의 개념을 큐에 도입한 자료구조.
데이터들이 우선순위를 가지고 있고, 우선순위가 높은 데이터가 먼저 나간다.
큐 : 가장 먼저 들어오는 데이터
우선순위 큐 : 가장 우선순위가 높은 데이터
순으로 삭제된다.
* 우선순위 큐의 이용사례
- 시뮬레이션 시스템
- 네트워크 트래픽 제어
- 운영체제 작업 스케줄링
- 수치 해석적인 계산
* 우선순위 큐는 배열, 연결리스트, 힙으로 구현이 가능하다. 이중에서 힙으로 구현하는 것이 가장 효율적이다.

[Heap]
* 완전 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조이다.
* 여러 개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조이다.
* 힙은 일종의 반정렬 상태(느슨한 정렬 상태)를 유지한다.
- 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있다는 정도
- 간단히 말하면 부모 노드의 키 값이 자식 노드의 키 값보다 항상 큰(작은) 이진 트리를 말한다.
* 힙 트리에서는 중복된 값을 허용한다. (이진 탐색 트리에서는 중복된 값을 허용하지 않는다.?)
<힙의 종류>
* 최대 힙(max heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
- key(부모 노드) >= key(자식 노드)
* 최소 힙(min heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
- key(부모 노드) <= key(자식 노드)

<힙의 구현>
* 힙을 저장하는 표준적인 자료구조는 배열이다.
* 구현을 쉽게 하기 위하여 배열의 첫번째 인덱스인 0은 사용되지 않는다.
* 특정 위치의 노드 번호는 새로운 노드가 추가되어도 변하지 않는다.
- 루트 노드의 오른쪽 노드의 번호는 항상 3이다.
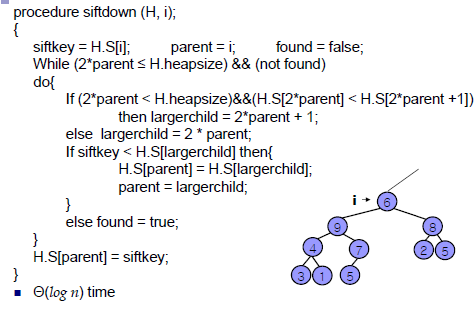
* 힙에서의 부모 노드와 자식 노드의 관계
- 왼쪽 자식의 인덱스 = (부모의 인덱스) * 2
- 오른쪽 자식의 인덱스 = (부모의 인덱스) * 2 + 1
- 부모의 인덱스 = (자식의 인덱스) / 2
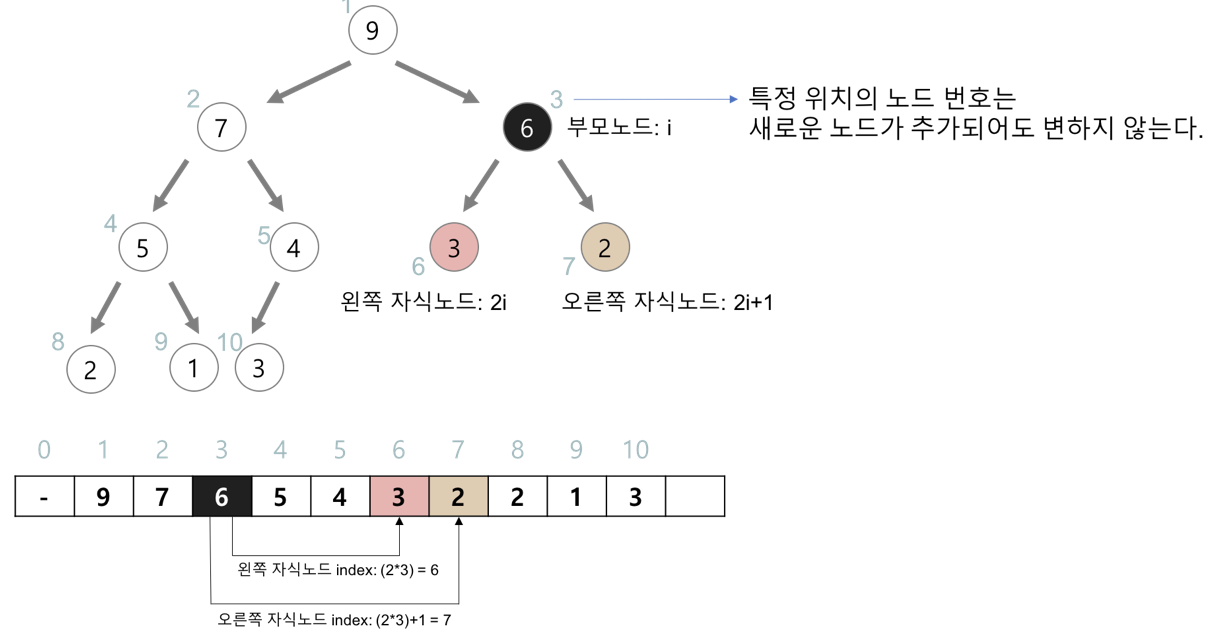
<힙의 삽입>
1. 힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 이어서 삽입한다.
2. 새로운 노드를 부모 노드들과 교환해서 힙의 성질을 만족시킨다.
(알고리즘2 코드 다시 보기 ....)


<힙의 삭제>
1. 최대 힙에서 최댓값은 루트 노드이므로 루트 노드가 삭제된다.
* 최대 힙에서 삭제 연산은 최닷값을 가진 요소를 삭제하는 것이다.
2. 삭제된 루트 노드에는 힙의 마지막 노드를 가져온다.
3. 힙을 재구성한다...?.....?????
(코드 다시보기 ㅠㅠ)
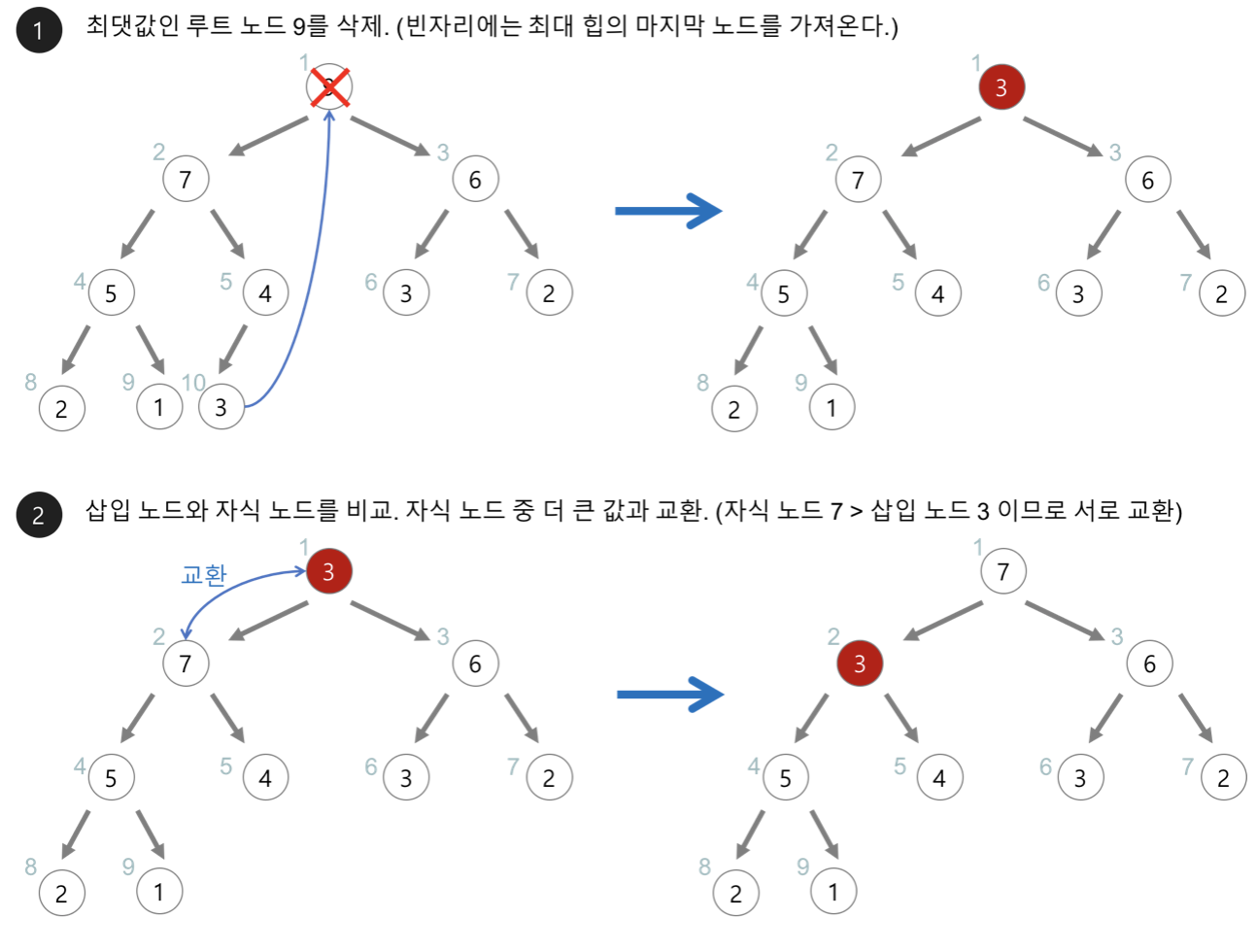

Q) 오일러 사이클이란?
어떤 그래프가 있다고 하고 그 그래프의 vertex들을 한번씩 지나면서 모든 edge를 다 지나가는 path가 존재하고, 출발지와 최종 도착지가 같으면 그 path를 오일러 사이클이라고 한다.
1. 모든 vertex v에 대해서 degree(v)가 짝수여야 한다. (degree: 어떤 vertex v에 연결된 edge의 수)
2. 모든 vertex가 (하나로) 연결되어있다. (?)
dfs로 구할 수 있다.
그래프의 모든 간선을 정확히 한번씩 지나서 시작점으로 돌아오는 경로.
Q) Shortest Path Problem, 최단경로 알고리즘
q) 다익스트라 알고리즘, 문제점, 해결방법
[최단거리 문제]
최단 경로 문제란 두 노드를 잇는 가장 짧은 경로를 찾는 문제.
Weighted Graph에서는 엣지 가중치의 합이 최소가 되도록 하는 경로를 찾으려는 것이 목적.
* 단일 출발(single-source) 최단 경로
: 단일 노드 v에서 출발하여 그래프 내의 모든 다른 노드에 도착하는 가장 짧은 경로를 찾는 문제 (다익스트라, 벨만-포드)
* 단일 도착(single-destination) 최단 경로
: 모든 노드들로부터 출발하여 그래프 내의 한 단일 노드 v로 도착하는 가장 짧은 경로를 찾는 문제. 그래프 내의 노드들을 거꾸로 뒤집으면 단일 출발 최단경로문제와 동일
* 단일 쌍(single-pair) 최단 경로 : 주어진 꼭지점 u와 v에 대해 u에서 v까지의 최단 경로를 찾는 문제
* 전체 쌍(all-pair) 최단 경로 : 그래프 내 모든 노드 쌍들 사이의 최단 경로를 찾는 문제. (플로이드-와샬)
[Optimal substructure]
최단거리의 중요한 속성.
다익스트리 알고리즘, 벨만-포드 알고리즘이 최단 경로를 찾을 때 쓰는 핵심 정리
* 최단 경로의 부분 경로는 역시 최단 경로이다.
D(s, v) = D(s, u) + w(u, v)
이와 같이 어떤 문제의 최적해가 그 부분문제들의 최적해들로 구성(contruct)될 수 있다면 해당 문제는 optimal substructure를 가진다고 말한다.
이 속성을 가지고 DP나 greedy를 적용해 문제를 효율적으로 풀 수 있다.
[edge relaxation]
최단경로를 구하는 알고리즘은 edge relaxation(변 경감)을 기본 연산으로 한다. 이는 지금까지 이야기한 최단경로 문제의 optimal substructure에서 파생된 것이다.
우선 시작노드 s에서 임의의 노드 z로의 최단경로를 구한다고 하자. 그리고 현재 시점에서 우리가 알고 있는 s-z사이의 최단거리 d(z)는 75, s-u사이의 최단거리 d(u)는 50이라고 하자.
그런데 탐색 과정에서 엣지 e를 경유하는 경로의 거리가 총 60이라고 한다면 기존에 우리가 알고 있는 d(z)보다 짧아서 기존 d(z)가 최단 경로라고 할 수 없게 된다. 이에 최단경로를 구성하고 있는 노드와 엣지정보, 그리고 거리의 합을 업데이트해준다. 이것이 바로 edge relaxation이다.
edge relaxation은 최단경로 알고리즘을 수행하는 과정에서 경로를 구성하고 있는 엣지 가중치의 합을 줄여나간다(relax)는 취지로 이런 이름이 붙은 것 같다 ...
[알고리즘 특성별 비교]
최단경로 알고리즘은 크게 다익스트라, 벨만-포드 알고리즘이 있다.
다익스트라 알고리즘은 엣지 가중치가 음수일 경우 동작하지 않는다.
벨만 포드 알고리즘의 경우 엣지 가중치가 음수여도 동작하자, negative cycle이 있을 경우 동작하지 않는다.
다익스트라의 계산복잡도는 O(|V|2 + |E|)
벨만-포드는 O(|V||E|)
[전체쌍 최단경로]
전체쌍(All-pair)최단 경로 문제는 Floyd-warshall 알고리즘이 쓰인다.
최단 경로 문제의 optimal substructure을 활용함.
[다익스트라]
다익스트라 알고리즘은 BFS을 기본으로 한다.
* 단점
다익스트라 알고리즘의 최대 단점은 가중치가 음수인 경우 작동하지 않는다는 것.
[Dijkstra's Algorithm for S.S.S.P]
* All-pairs shortest prob : Floyd Alg(DP)
(no negative-weight cycle)
* Single-Source Shortest Path Prob. : Dijkstra's Alg(Greedy)
* Simiar to Prim's Alg
Start with {v1}; //Source//
Choose nearest vertex from v1, ...
Y = {v1};
F = null // Shortest paths tree//
while not solved do {
Select v from V-Y nearest from v1,
using only Y as intermediates;
add v to Y;
add the edge touching v to F;
if Y = V then Exit;
}
*Weighted directed graph (no negative-weight edge)
Adjacency Matrix : Input
다익스트라 알고리즘-> 간선에 weight도 있을 때, BFS는 그냥 간선에서 최소 간선 .., 예제 그림들을 보면 알 수 있쥬?
그래프의 한 노드에서 연결된 다른 노드들로 가는 최단거리를 구하는 알고리즘.
만약 모든 노드 쌍간의 최단 거리를 구하고 싶다면 N개의 각 정점에 대해 해당 정점을 출발점으로 하는 다익스트라 알고리즘을 수행해야 한다.
(이러한 상황에서는 이후에 다룰 플로이드 워셜 알고리즘이 다익스트라를 N번 수행하는 것보다 유효하다. )


다익스트라 알고리즘은 한 노드에서 다른 노드로 가는 최단 경로를 구성하는 간선들은 항상 최단 거리를 갖는다는 아이디어를 기반으로 한다.

동작과정은 BFS와 비슷하다. 하지만 BFS는 큐를 이용, 다익스트라는 우선순위 큐(MIN-HEAP)를 이용하여 방문할 정점과 방문할 정점까지의 거리를 넣어준다는 것이 차이점이다. (가중치로 우선순위를 부여할 수 있으므로?)
[시간복잡도]
모든 간선은 한 번씩 확인해야 하므로, 간선들을 검사하는데 O(E)의 시간이 걸린다. (E는 간선의 개수), 우선순위 큐에 들어가는 원소는 간선마다 최대 1번씩 들어가므로 O(E)이고, 이를 한번 삽입, 삭제하는데 O(logN)만큼 걸리기 때문에 시간복잡도는 O(ElogE)이다.
총 시간 복잡도 : O(E+ElogE) => O(ElogE)
[슈도코드]

[벨만-포드 알고리즘]
* negative cycle
다익스트라 알고리즘과 달리 벨만-포드 알고리즘은 가중치가 음수인 경우에도 적용이 가능하다. 그러나 음수 가중치가 싸이클을 이루고 있는 경우에는 작동하지 않는다.
[Single-Sourc Shortest Paths: (Bellman and Ford's algorithm)
* Negative weights allowed
* Let dk(v, u) = shortest path from v to u
involving <= k edges
* Base
- d1(v, u) = length(v, u)
* Recurrence relation
- dk+1(v, u) = min{ dk(v, u), dk(v, i) + length(i, u) }
[C++ code for Bellman and Ford's Algorithm]
void Graph::BellmanFord(const int n, const int v)
{
for(int i = 0; i < n; i++) dist[i] = length[v][i];
for(int k = 2; k < n; k++)
for(each u such that u != v and
u has >= 1 incoming edge)
for(each edge <i, u> in the graph)
if(dist[u] < dist[i] + length[i][u])
dist[u] = dist[i] + length[i][u];
}

벨만포드 알고리즘은 다익스트라 알고리즘과 마찬가지로 어느 한 정점에서 나머지 정점까지의 거리를 구하는 알고리즘이다. 하지만 다익스트라와는 다르게 음수 가중치를 갖는 그래프에서도 동작을 하며, 음수 사이클을 찾아내는 기능도 가지고 있다.
하지만 알고리즘의 수행 시간이 일반적으로 다익스트라보다 느린 것이 단점.
기본적인 아이디어는 다익스트라와 비슷하다. - dist(distance)배열을 만들어서 최단 거리에 근접하게 계속 갱신시켜주는방식. 하지만 우선순위 큐를 이용하여 간선에 연결된 정점의 최단 거리를 갱신하는 다익스트라와 달리, 모든 정점의 최단거리를 구할 때까지 모든 간선들을 여러 번 확인하여 최단거리를 구한다는 것이 차이점이다.


구현방법은 다익스트라와 비슷한 전처리 과정으로 dist 배열을 만들고, 시작 정점의 dist는 0으로 만든 뒤, 모든 간선을 확인하는 것이다.
간선이 u->v라면 dist[v]와 dist[u] + W[E] (간선의 가중치)를 비교하여 갱신해주고, 이러한 과정을 v번 반복하면 된다.
과정을 v번 반복하는 이유는 시작점에서 어떤 u까지 가는 간선의 개수는 최대 V-1개 이고, 최악의 경우에 한차례마다 한간선씩 갱신이 된다고 해도 V-1번이면 찾을 수 있다.
그러면 왜 V-1번이 아니라 V번 반복할까? => 음수 사이클이 있을 경우 데이터 범위의 제한이 없을 경우 무한하게 갱신되기 때문이다. (음수 사이클의 경우에는 V번째에 갱신이 되므로)
이러한 특징은 새로운 최단 거리를 찾을 때마다 갱신해주는 다익스트라에서는 찾을 수 없는 특징이다.
[슈도코드]


[다익스트라 vs 벨만포드 비교]
| 다익스트라 | 벨만포드 |
| Greedy | DP |
| 음수엣지 있으면 x | 음수 엣지 있어도 O |
| 사이클이 있으나 없으나 동일 | 사이클이 없으면 빠르게 수행가능 |
| internet routing 사용x | internet routing 사용 가능 |
| O(e logn) | O(ne) |
[출처]
경북대학교 유관우 교수님 알고리즘1, 알고리즘2 강의자료
blog.naver.com/qbxlvnf11/221377612306
최단 경로 문제: 다익스트라 알고리즘과 벨만-포드 알고리즘
최단 경로(Shortest path) 문제는 주어진 두 노드 사이의 경로들 중에서 최소 비용인 경로를 찾는 것입니...
blog.naver.com
힙과 힙 정렬 (Heap & Heap Sort) 요약 및 관련 자료
Jihun's Development Blog
cjh5414.github.io
<히프> 기본 개념과 삽입 삭제 알고리즘 정리
# 히프의 개념 히프(heap)는 "더미"라는 뜻이다. 히프는 여러 개의 값들 중에서 가장 큰 값이나 가장 작은 값을 빠르게 찾아내도록 만들어진 자료구조이다. 히프는 간단히 말하면 부모 노드의 키
mattlee.tistory.com
gmlwjd9405.github.io/2018/05/10/data-structure-heap.html
[자료구조] 힙(heap)이란 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
[알고리즘] 퀵 정렬(quick sort)이란 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
zeddios.tistory.com/93?category=682196
NP-Hard, NP-Complete
ㅎㅎ 안녕하세요 :) 이전글에서 P와 NP의 개념에 대해서 아주 길게.. 설명드렸는데... 조금 이해가 가셨나요 ㅠㅠ? 궁금한점이 있다면 댓글이나 채널서비스를 이용해서 바로 질문해주세요!! 오늘�
zeddios.tistory.com
ratsgo.github.io/data%20structure&algorithm/2017/11/25/shortestpath/
최단 경로 문제 · ratsgo's blog
이번 글에서는 최단 경로 문제(Shortest Path Problem)를 살펴보도록 하겠습니다. 이 글은 고려대 김선욱 교수님과 역시 같은 대학의 김황남 교수님 강의와 위키피디아를 정리했음을 먼저 밝힙니다. ��
ratsgo.github.io
github.com/WeareSoft/tech-interview/blob/master/contents/network.md
WeareSoft/tech-interview
:loudspeaker::person_frowning: tech interview. Contribute to WeareSoft/tech-interview development by creating an account on GitHub.
github.com
'Study > 면접' 카테고리의 다른 글
| [대학원] 면접준비 - 네트워크 (0) | 2020.05.16 |
|---|---|
| [대학원] 면접준비 - 이산수학 (0) | 2020.05.16 |
| [대학원] 면접준비 - 데이터베이스 (0) | 2020.05.16 |
| [대학원] 면접준비 - 운영체제 (0) | 2020.05.15 |



